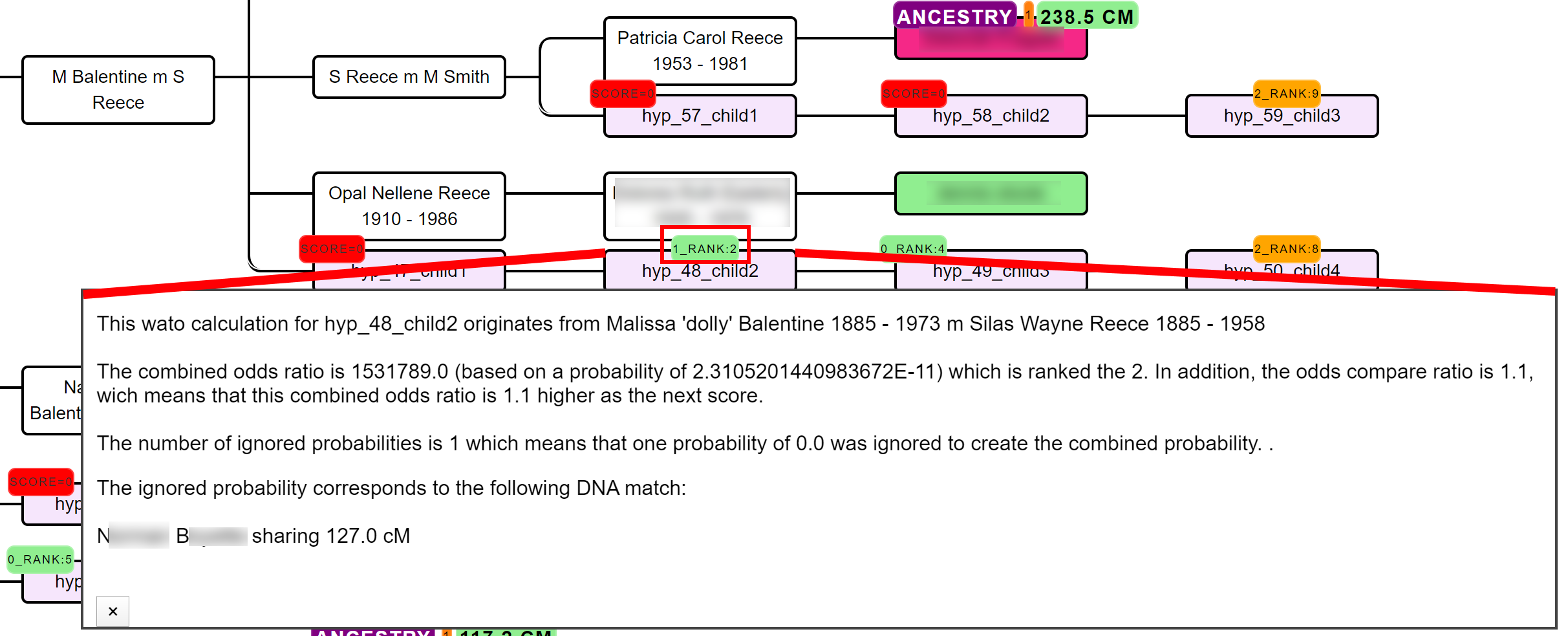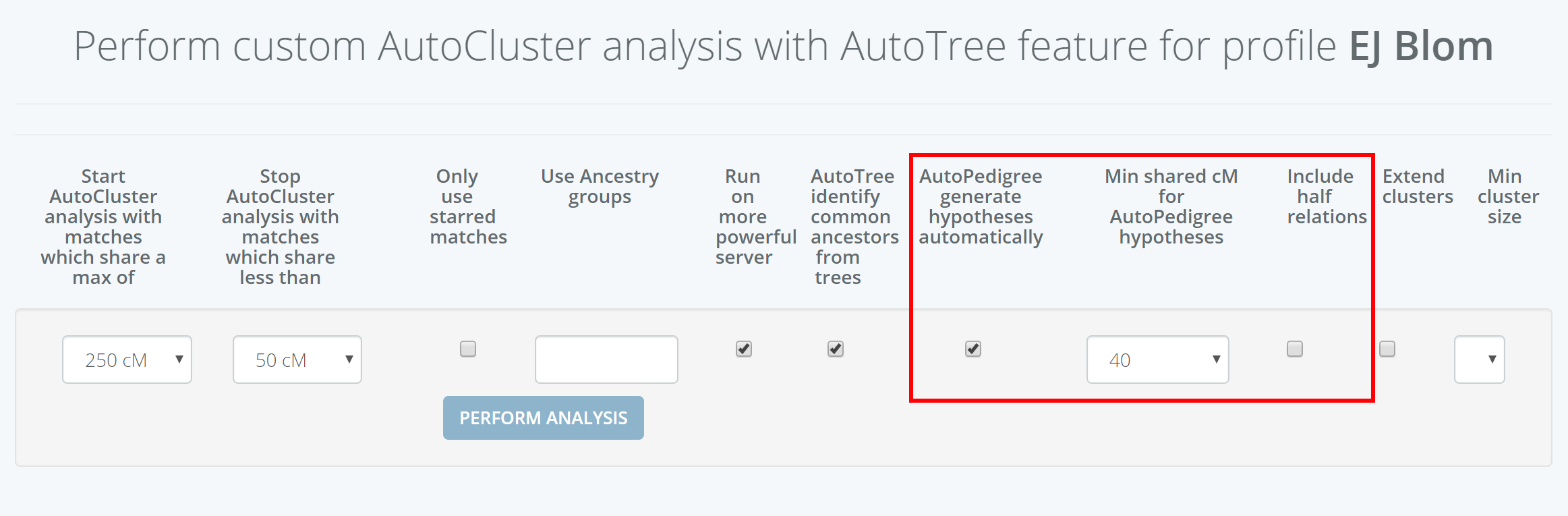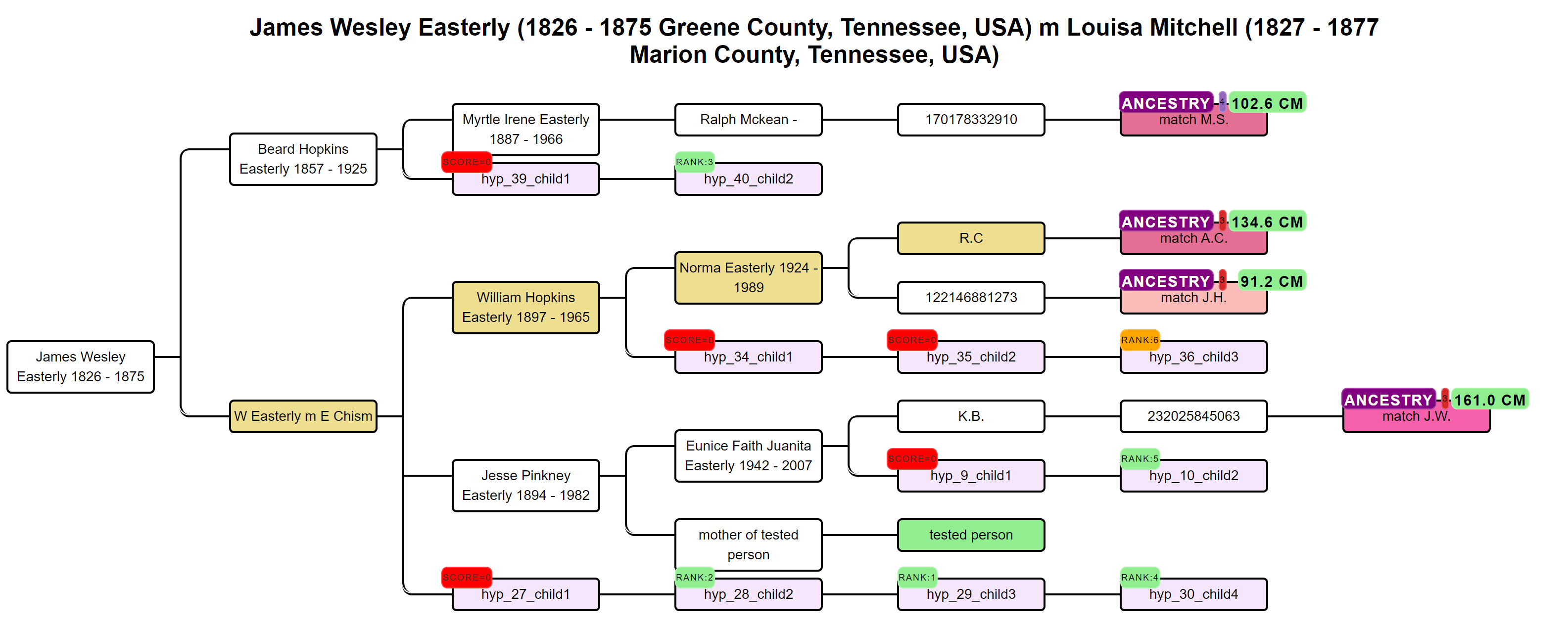
AutoPedigree concepts
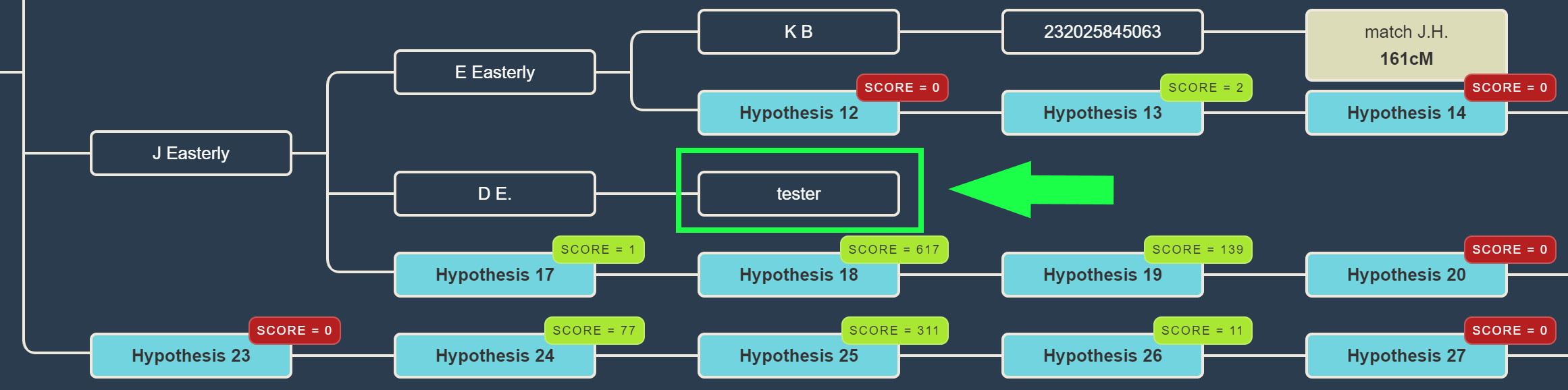
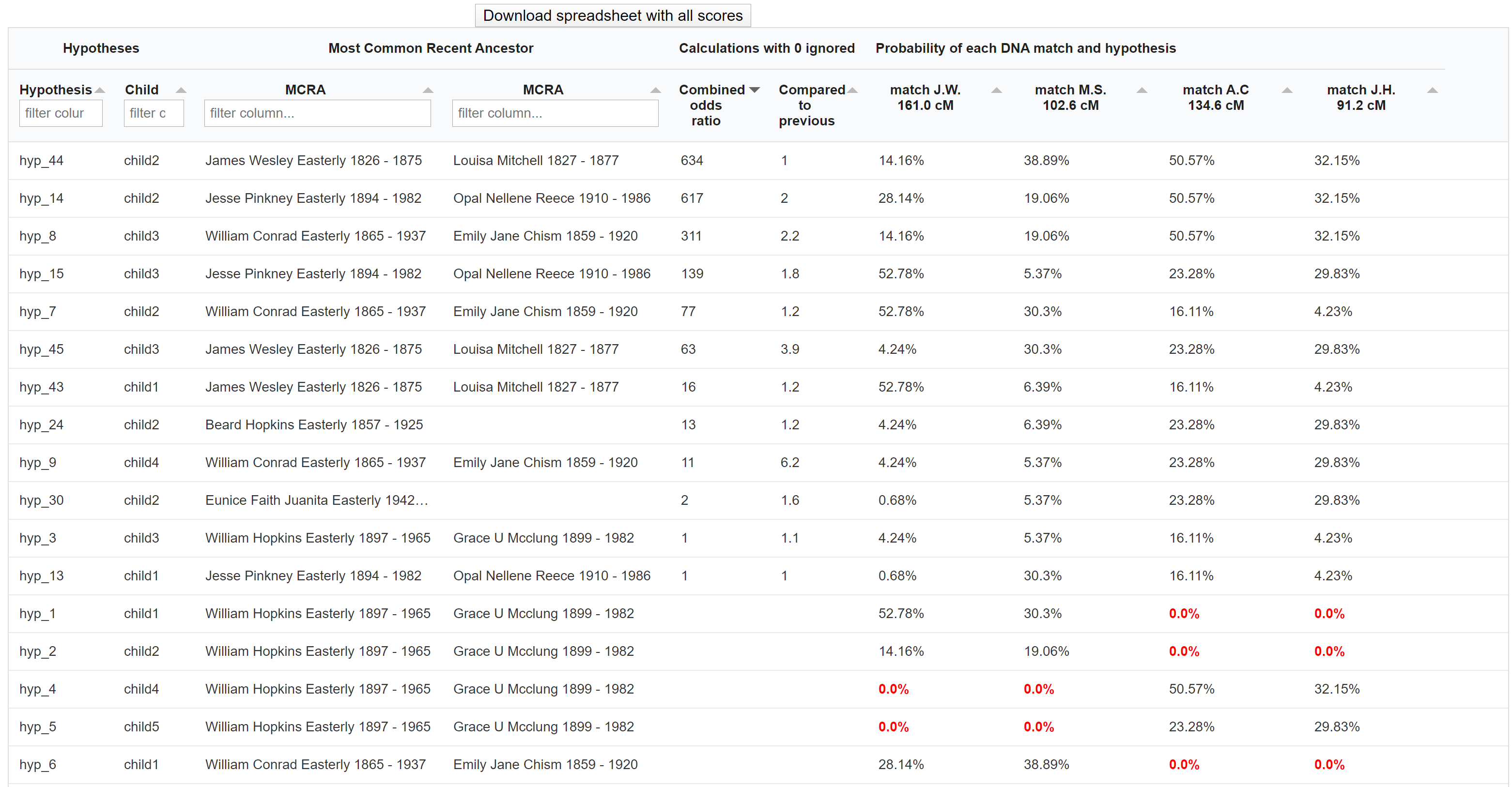
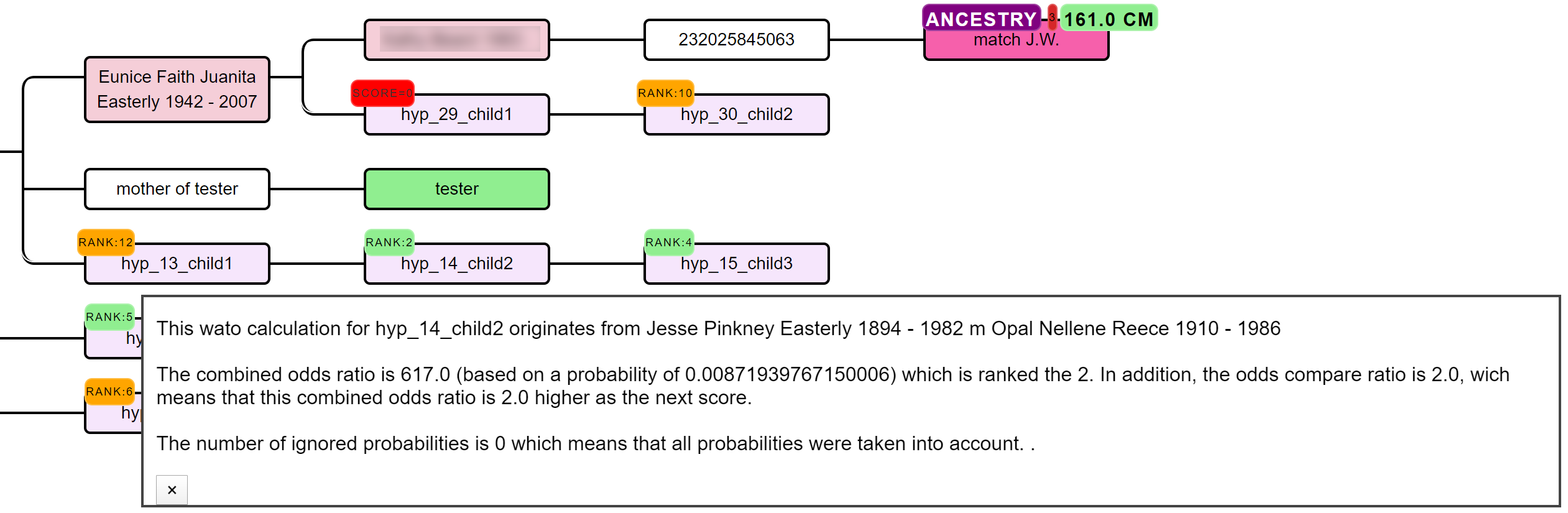
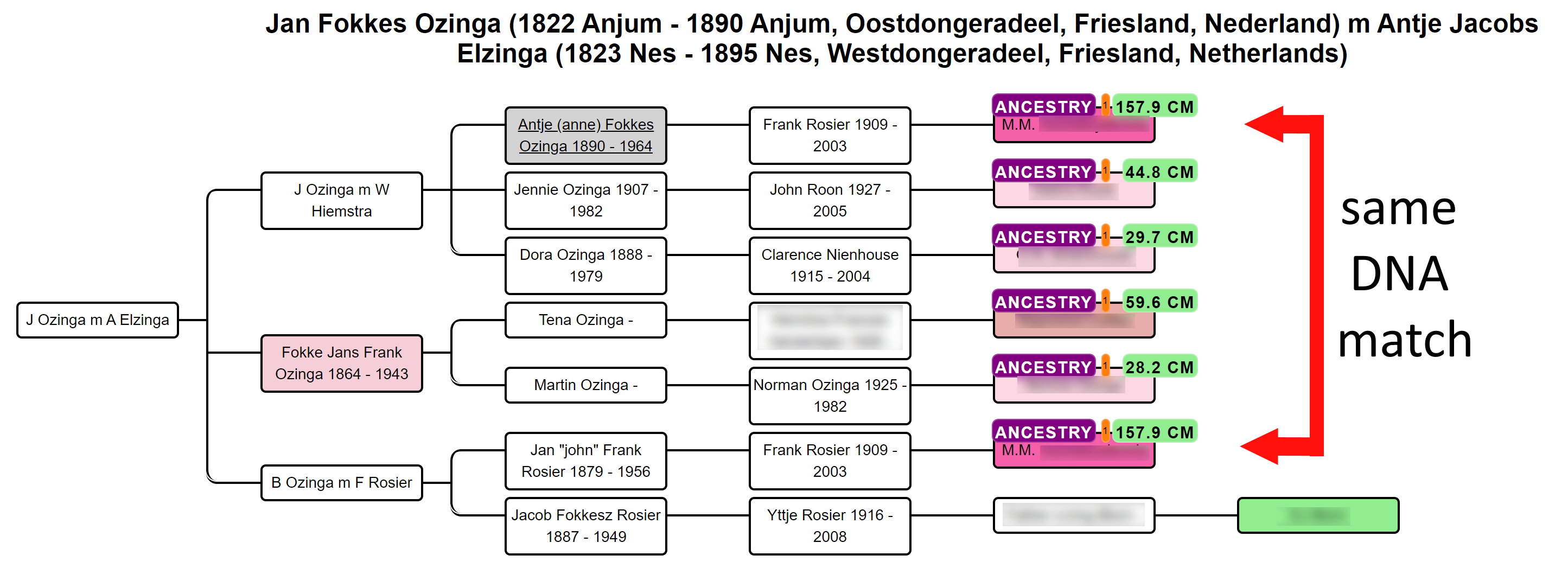
In short, the AutoPedigree feature automates the generation and testing of hypotheses using reconstructed trees from AutoTree. Based on the common ancestors from the reconstructed trees, we create siblings for each of the identified ancestors. Next, we generate descendants (also called hypotheses) that could serve as a hypothesis. What that means is the following, each generated descendant could represent the actual test taker (for instance an adoptee). But given the cM values of the DNA matches in the tree, some generated descendants are more probable than others. This probability is a measure of how likely a certain relationship is to occur.
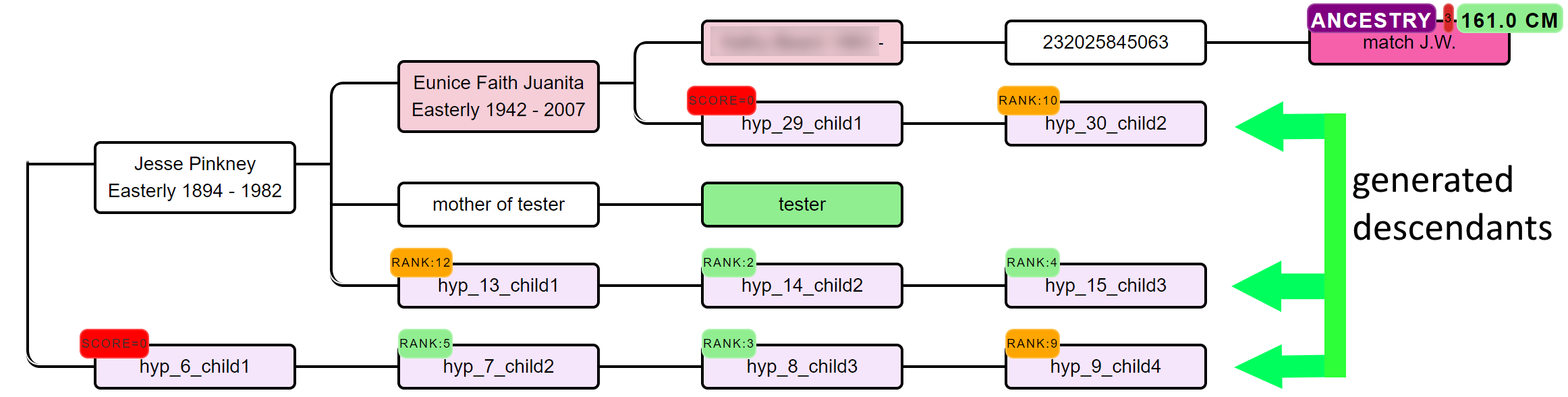
AutoPedigree concepts
In short, the AutoPedigree feature automates the generation and testing of hypotheses using reconstructed trees from AutoTree. Based on the common ancestors from the reconstructed trees, we create siblings for each of the identified ancestors. Next, we generate descendants (also called hypotheses) that could serve as a hypothesis. What that means is the following, each generated descendant could represent the actual test taker (for instance an adoptee). But given the cM values of the DNA matches in the tree, some generated descendants are more probable than others. This probability is a measure of how likely a certain relationship is to occur.