AutoPedigree
AutoPedigree is a feature that employs the AutoTree predictions. It is developed to identify how a person, for instance, an adoptee, fits into a reconstructed AutoTree.
Key Features
AutoPedigree concepts
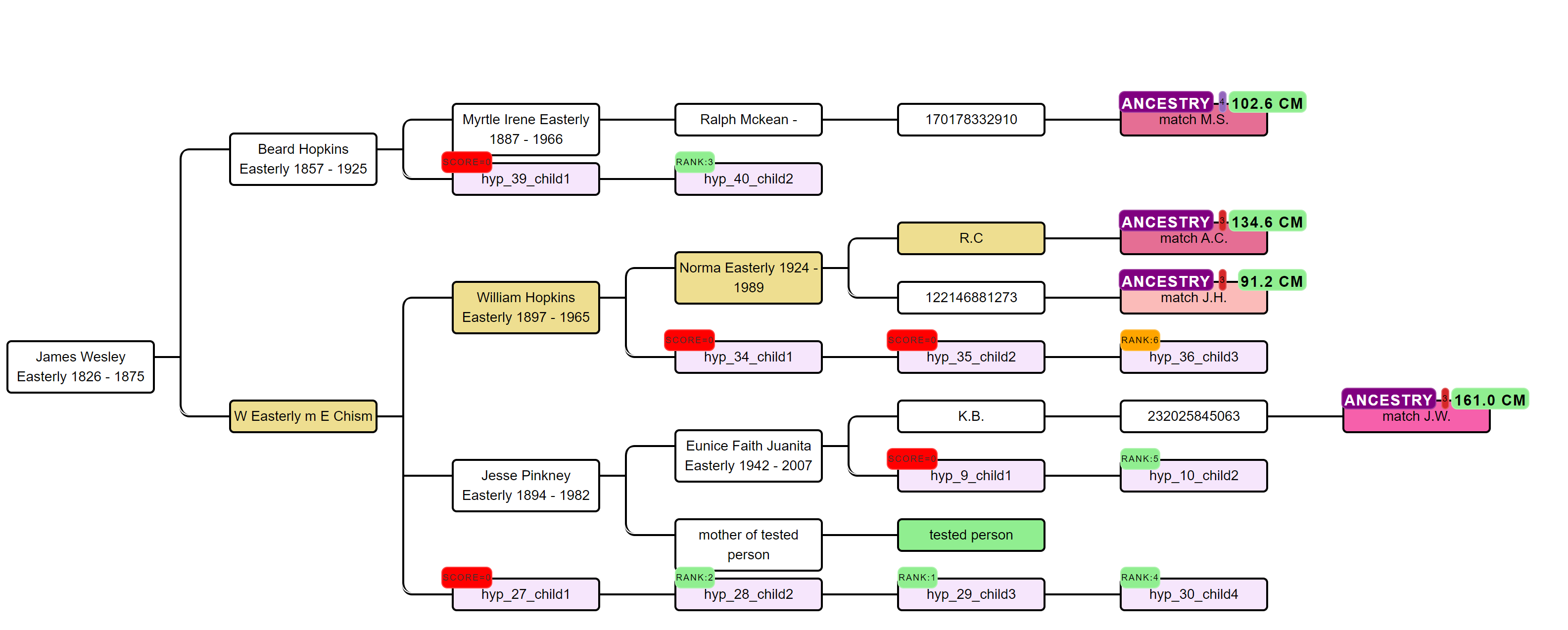
In short, the AutoPedigree feature automates the generation and testing of hypotheses using reconstructed trees from AutoTree.Based on the common ancestors from the reconstructed trees, we create siblings for each of the identified ancestors. Next, we generate descendants (also called hypotheses) that could serve as a hypothesis.
What that means is the following, each generated descendant could represent the actual test taker (for instance an adoptee). But given the cM values of the DNA matches in the tree, some generated descendants are more probable than others. This probability is a measure of how likely a certain relationship is to occur.
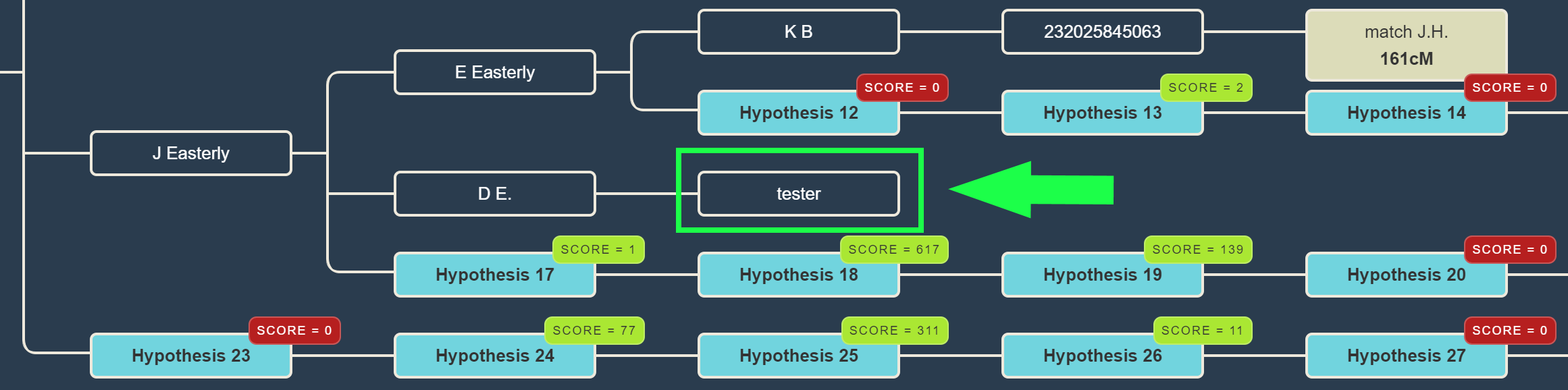
Combining probabilities
By multiplying each of the probabilities for each of the DNA matches in the tree, a score can be calculated for certain generated hypotheses. This type of analysis can also manually be performed using the online WATO tool. The same probabilities are also provided by the shared cM project tool, for instance, a 250 cM match has a 62% probability of being a 2C.
All generated AutoPedigree trees are available in the WATO format, allowing users to import them into WATO. This allows for further tweaking of the trees, for instance if the AutoTree wrongly identified a common ancestor. Also, matches from other companies that are known to be descendants as well can then be added.
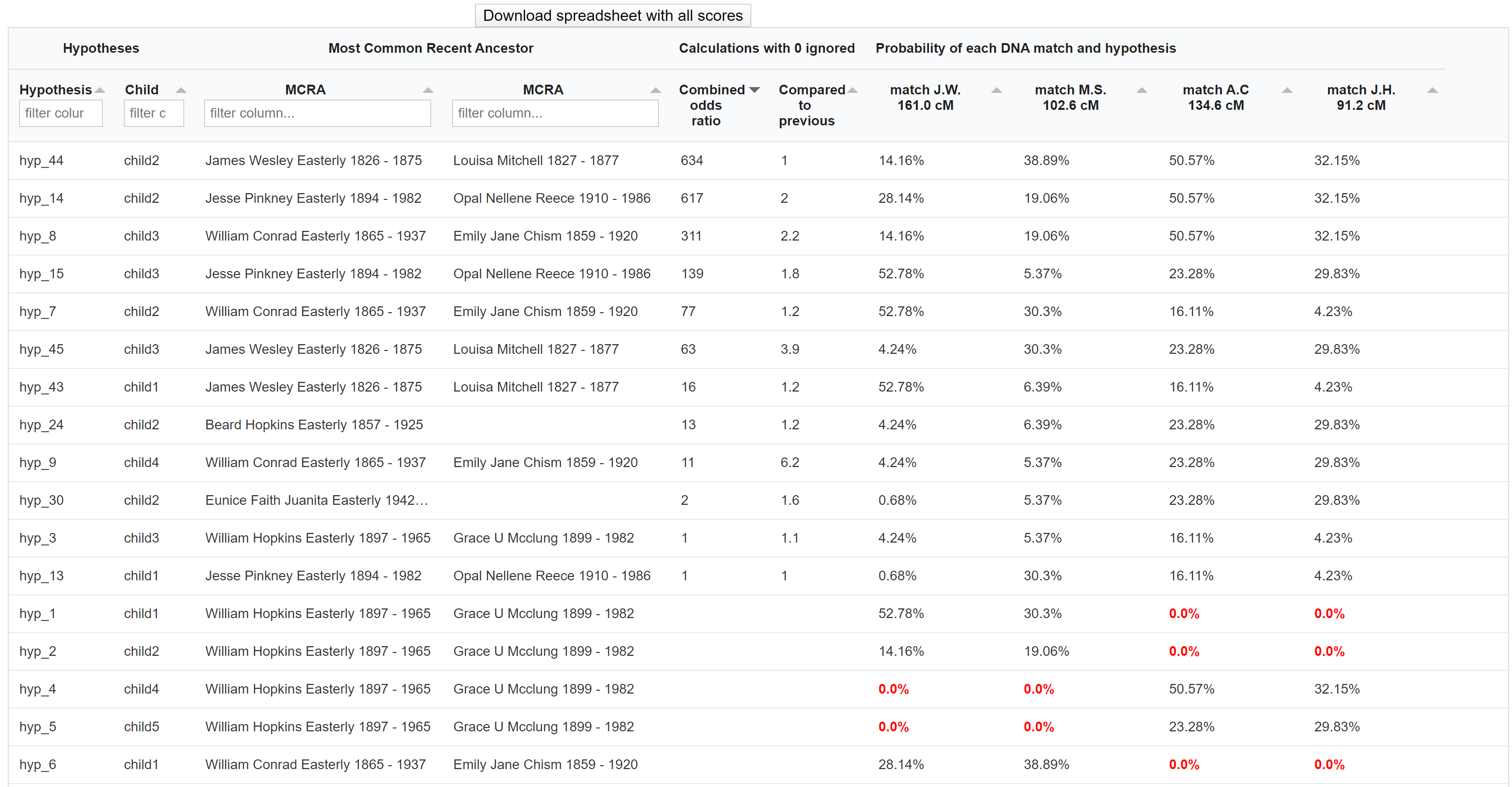
AutoPedigree scores table
The table underneath the visualized AutoPedigree tree summarizes the different hypotheses. Each row represents a hypothesis, the MRCA and the ranked combined odds ratios. This odds ratio score is calculated based on the probability of that hypothesis divided by the smallest probability of another hypothesis. Next, we compare the score to the next, slightly smaller, score and calculated the ratio between them. For instance, if the best combined odds ratio is 200 and the second best is 50, the compared score would be 4 (200 divided by 50). The last columns show the probability of each DNA match and the generated hypothesis.
Some hypotheses contain probabilities that are 0.0%, indicating that this relationship is not possible when taking into account the cM value of the DNA match and the proposed genealogical link. For instance, a DNA match that shares 200 cM cannot have a relationship of a 4C.
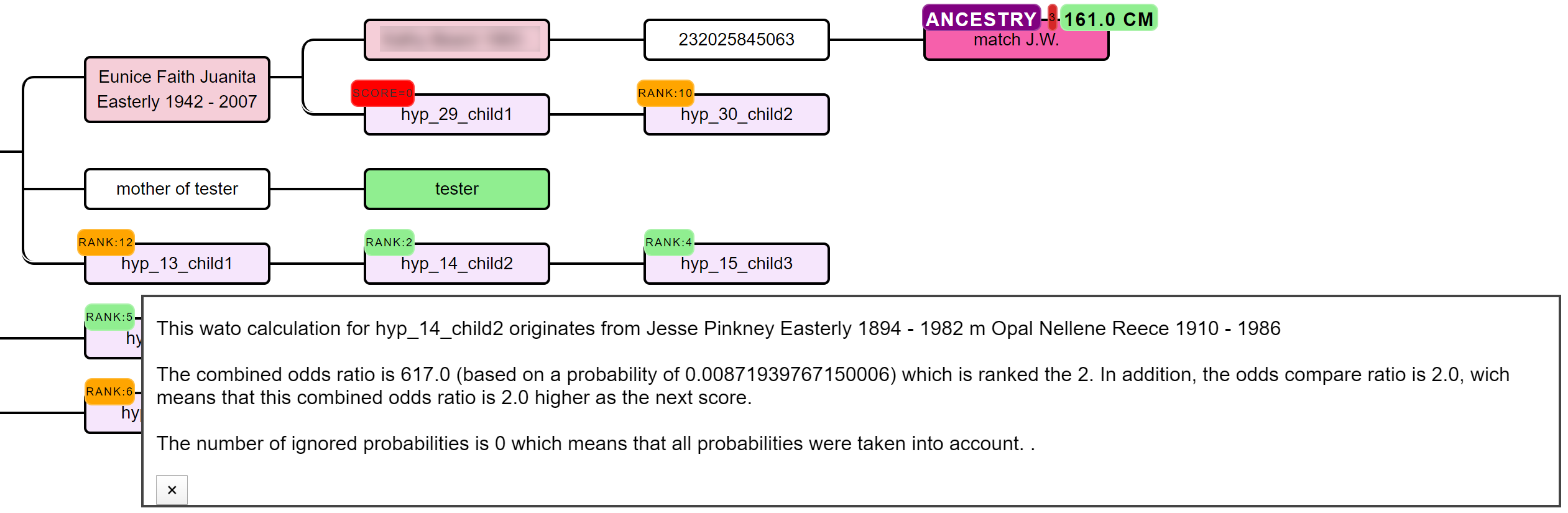
Visualized hypotheses
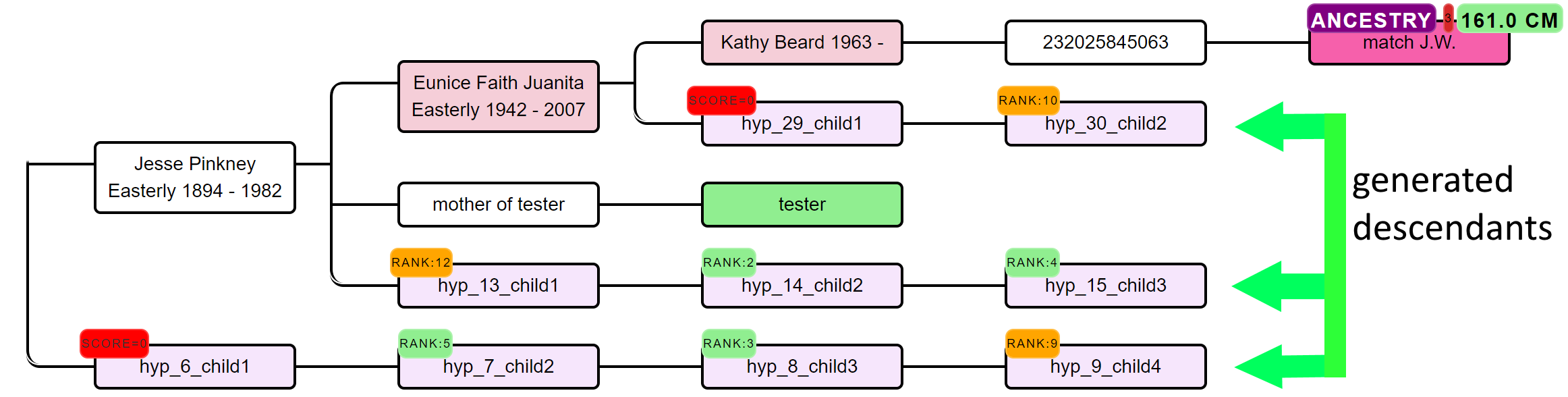
The generated hypotheses are visualized as descendants in the reconstructed AutoTree visualizations. For instance, hyp_14_child2 represents the 14th hypothesis and the second child. Instead of supplying the scores, we are providing the rank of the score in a badge. Scores that have a probability of 0 are placed in a red badge, the top 5 scores are placed in a green badge and the remainder in an orange badge.
Upon clicking on the badge, a popup will appear that holds more information concerning the calculation of the score. A lot of hypotheses are tested for AutoPedigree. Therefore, to improve the visibility, we prune the AutoTree tree by only displaying generated descendants if positive probabilities are available for that branch.
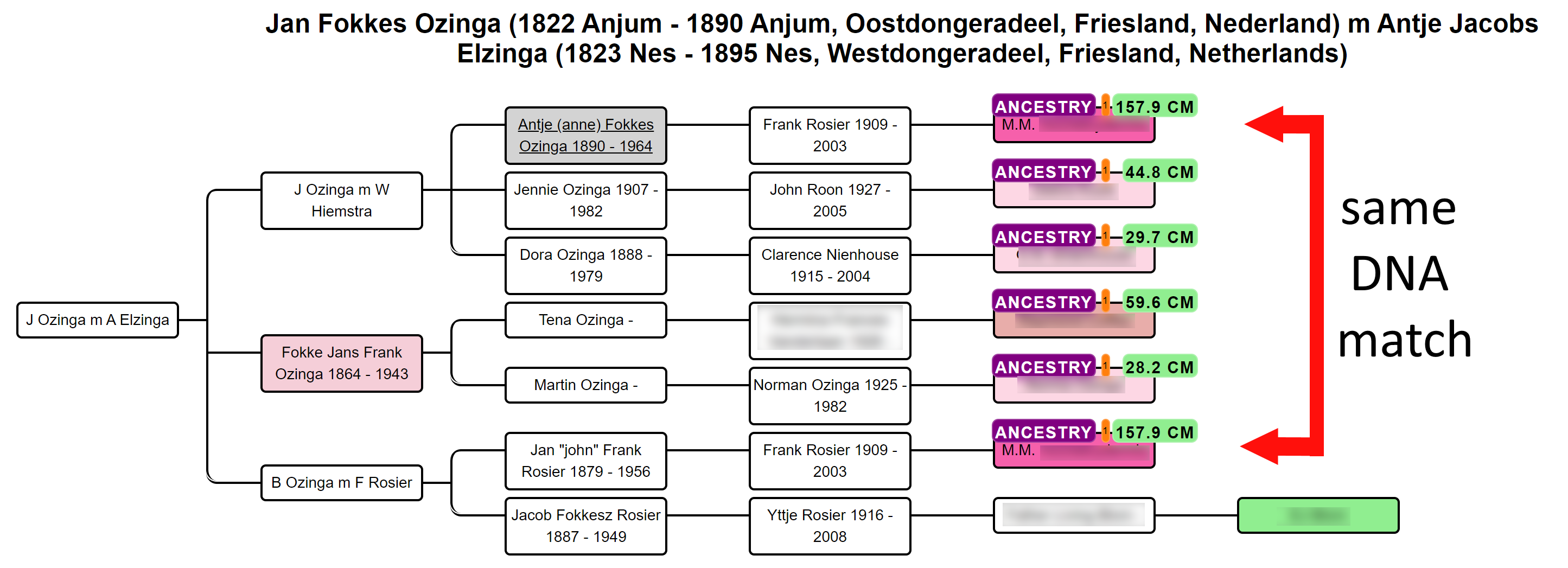
Endogamy and/or pedigree collapse
In some cases, a DNA match has multiple links with the tested person, for instance, DNA match M.M. that shares 157.9 cM and has common ancestor J Ozinga and B Ozinga. The amount of cMs that is shared with the tested person is therefore inflated. To correct for this, we employ an approach that divides the amount of shared cM based on the different genealogical paths.
We, therefore, attribute a larger fraction of cM to the DNA match if the tested hypothesis has a shorter path to the hypothesis as compared to the other path(s). Despite this measure, caution should be taken when encountering these DNA matches. The grey cells in the AutoCluster charts can be indicative of matches that are linked to more clusters and therefore linked via multiple ancestors.
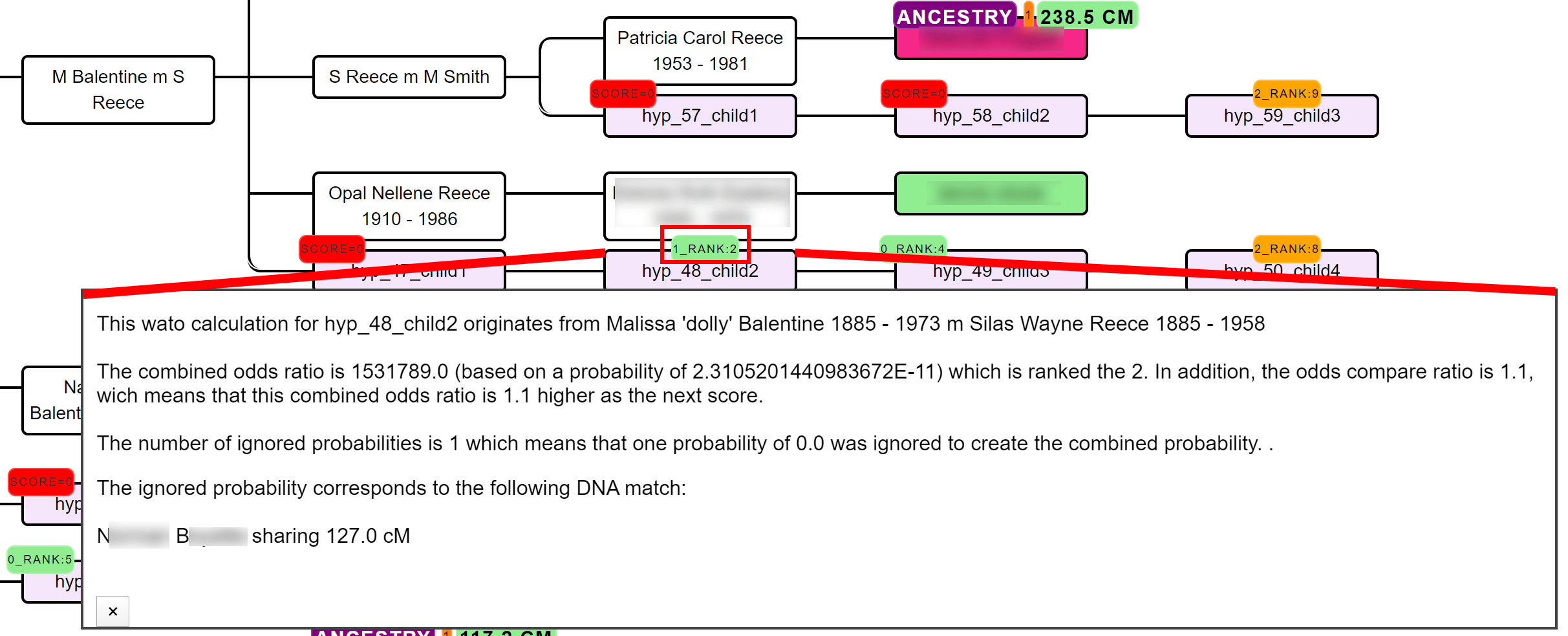
Ignored probabilities
A single inaccurate hypothesis in the tree can potentially nullify the overall hypothesis, making its score zero. Unfortunately, these hypotheses are sometimes inevitable, for instance, because a match is related via multiple genealogical links whereas only one line is identified. In this case, you might end up with a predicted 4C (based on the reconstructed tree) that shares much more DNA with the tester as is expected based on the 4C relationship.
If necessary, we therefore also perform the same automated analysis while ignoring one or two of these cases. If the rank badge starts with a digit, this digit will represent the number of ignored probabilities (2_RANK:4 indicates a hypothesis ranked 4th for which 2 probabilities were ignored).
AutoPedigree examples
Explore some visualizations created by the AutoPedigree tool.How to get started*
*AutoPedigree works exclusively with FamilyTreeDNA profiles.
Availability across different companies
Compare the availability and features of the AutoPedigree tool across five major genetic testing companies.FTDNA
- Automated retrieval supported
23andme
- not supported
Ancestry
- not supported
MyHeritage
- not supported
GEDmatch
- Automated retrieval not supported via Genetic Affairs
- Available via GEDmatch
Check out our AutoPedigree FAQ
Our AutoPedigree FAQ section covers everything you need to know about AutoPedigree
